


The Unicode Consortium has released a revised draft of standards for encoding Egyptian hieroglyphics, meaning that they may soon be available to use on mobile phones, computers, and other digital devices.
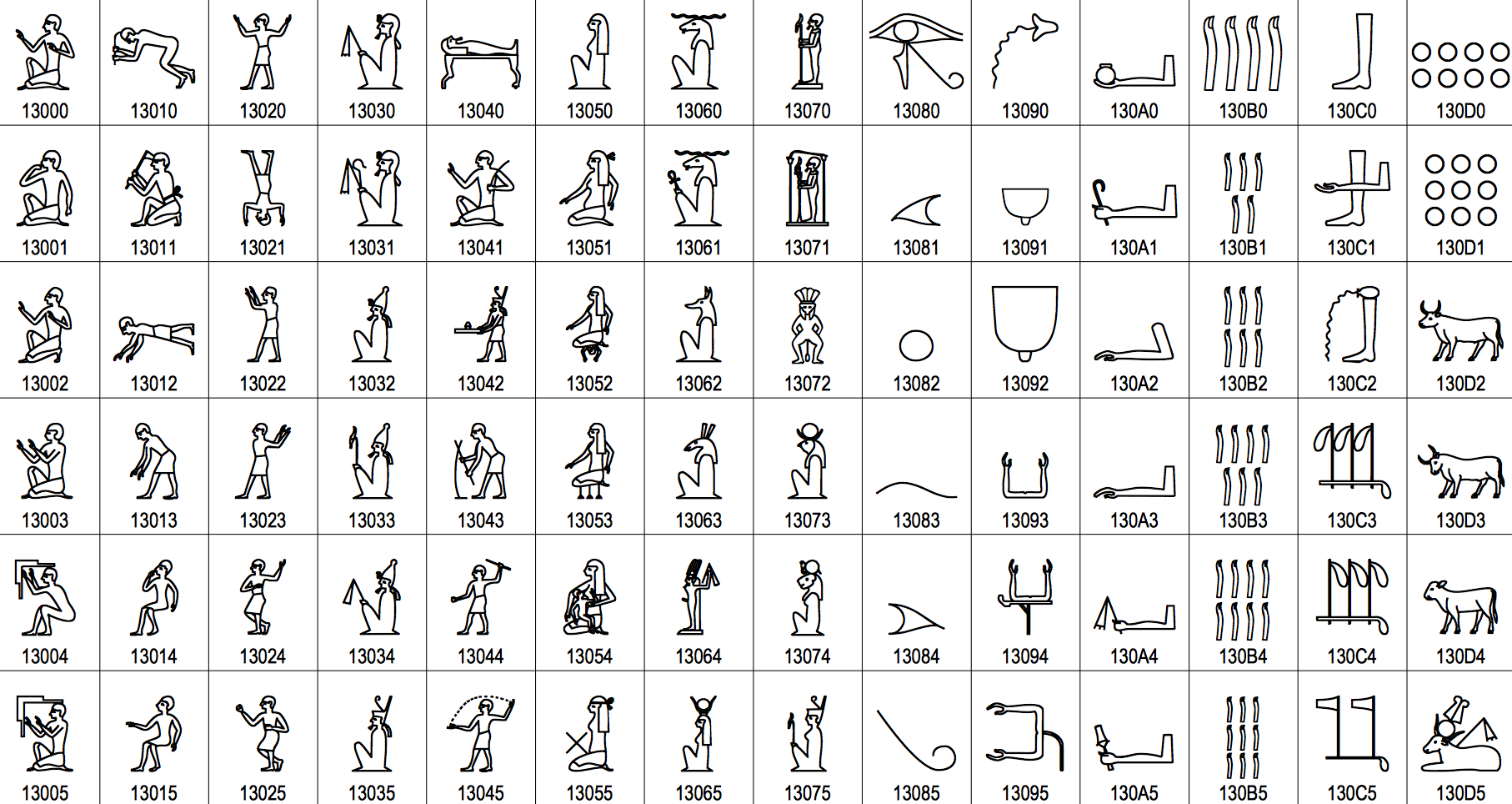
The proposal explains how Egyptian hieroglyphs evolved from a set of just over 700 characters during most of the classical period (which encompasses the Old Kingdom, Middle Kingdom, and New Kingdom), to a repertoire of over 7000 characters during the Graeco-Roman period. The larger set, it states, is generally known as ‘Ptolemaic’, despite the fact that many of the extensions were in use during the classical period as well.
In addition, the increase in characters was accompanied by an growth in the phonetic values ascribed to a single glyph, which could exceed 20 readings.
The intention, the proposal states, is to “set the base for the encoding of the extended set, allowing Egyptologists to communicate data in a unified encoding platform.” Then, each element of the set can be indexed in a database where addition information relating to the sound, semantic, sources, description etc, can be conveyed.
Reporting on the matter, Hyperallergic states that it is “part of a larger effort between the Unicode Consortium, ancient linguists, font designers, and the US federal government to attempt to study, preserve, and then digitally represent ancient and endangered languages through the use of computer code.” The ultimate goal, it says, is to provide Egyptologists with a method of easily transmitting what was written on inscriptions, papyri, wall paintings, and other sources of Hieroglyphs, and it could also result in a more popular knowledge of the ancient language. In theory, it could be assimilated into popular language-learning apps such as Duolingo.
Egyptian hieroglyphs have in fact been defined within Unicode since version 5.2, released in 2009, but the range was limited and did not include those from the Graeco-Roman period, nor was there an agreed method for placing the hieroglyphs into groups.
Unicode, which began in 1987, aimed to create a universal character set that could be understood across operating systems, and functions by assigning a unique number to each character. It is most famous for its standardisation and encoding of emoji.
The Hieroglyphic script is particularly challenging to encode, because it consists of logograms (signs representing language units), phonograms (signs representing sounds), and determinatives (signs joining together and clarifying logograms and phonograms).






Comments (0)